
As the use of generative AI tools continues to rise, Meta is adding some new controls that’ll enable users to opt out of having their personal data included in AI model training, via a new form on its Privacy Center hub.
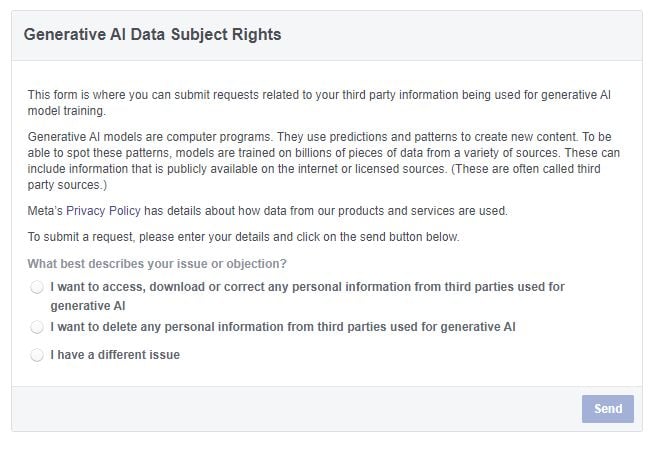
As you can see in this form, Meta will now enable users to “delete any personal information from third parties used for generative AI” via a simple form feedback process, which will provide more control over such for regular users.
Meta has also added a new generative AI overview in its Privacy Center, which includes a broad description of the various ways in which generative AI models are trained, and the part that your Meta data can play in that process.
As per Meta:
“Since it takes such a large amount of data to teach effective models, a combination of sources are used for training. These sources include information that is publicly available online and licensed information, as well as information from Meta’s products and services. When we collect public information from the internet or license data from other providers to train our models, it may include personal information. For example, if we collect a public blog post it may include the author’s name and contact information. When we do get personal information as part of this public and licensed data that we use to train our models, we don’t specifically link this data to any Meta account.”
Based on this, Meta’s looking to increase people’s awareness, and control over such usage.
“We have a responsibility to protect people’s privacy and have teams dedicated to this work for everything we build. We have a robust internal Privacy Review process that helps ensure we are using data at Meta responsibly for our products, including generative AI. We work to identify potential privacy risks that involve the collection, use or sharing of personal information and develop ways to reduce those risks to people’s privacy.”
The update comes as the new EU DSA rules come into effect, which will also provide more control over personal data, and how it’s used by online platforms. As such, it could be that Meta’s looking to get ahead of the next EU provisions with this update, with the DSA already specifying that social platforms need to provide more data control options as standard in their apps.
It seems inevitable that generative AI usage will also be incorporated into the same, while many artists are also pushing for new laws that would enable them to remove their works from the training sets for AI models.
Though it remains a legal gray area. The use of publicly available content to create something new, even if that new creation is derivative, is not a consideration that’s been built into copyright law as such, and it’ll take some time, and various test cases, to update the rules around unintended or undesired use. As such, providing the option for people to remove their own information, and work, will become a much bigger focus moving forward, which Meta is looking to get ahead of the curve on here.
Meta also notes that it’s looking to make a bigger push into generative AI soon.
“We’re investing so much in this space because we believe in the benefits that generative AI can provide for creators and businesses around the world. To train effective models to unlock these advancements, a significant amount of information is needed from publicly available and licensed sources. We keep training data for as long as we need it on a case-by-case basis to ensure an AI model is operating appropriately, safely and efficiently. We also may keep it to protect our or other’s interests, or comply with legal obligations.”
You can expect the usage regulations around generative AI to evolve fast, especially now that the highly litigious record publishing industry is involved.
With that in mind, it makes sense for Meta to get ahead of the next big shift.
You can read Meta’s full “Privacy and Generative AI” data usage overview here.

