
As promised by Twitter chief Elon Musk earlier this month, today, Twitter has published its recommendation algorithm code on GitHub for everyone to see, while it’s also posted a new overview of how its tweet recommendation algorithm works, providing new insights into what dictates the order in which tweets are displayed.
As explained by Twitter:
“On GitHub, you’ll find two new repositories (main repo, ml repo) containing the source code for many parts of Twitter, including our recommendations algorithm, which controls the Tweets you see on the For You timeline. For this release, we aimed for the highest possible degree of transparency, while excluding any code that would compromise user safety and privacy or the ability to protect our platform from bad actors, including undermining our efforts at combating child sexual exploitation and manipulation.”
Also important to note that Twitter hasn’t the weighting info connected to each element – i.e. how much emphasis each factor gets in driving the final output results.
So it’s not every detail, but it does provide high-level insight into how Twitter’s algorithms work, while Twitter’s also provided a more layman’s explanation of the system, in order to help people understand how it decides what you’ll see in your timeline every time you open the app.
As per Twitter:
“The foundation of Twitter’s recommendations is a set of core models and features that extract latent information from Tweet, user, and engagement data. These models aim to answer important questions about the Twitter network, such as, “What is the probability you will interact with another user in the future?” or, “What are the communities on Twitter and what are trending Tweets within them?” Answering these questions accurately enables Twitter to deliver more relevant recommendations.”
That last element is important, and aligns with what Garbage Day’s Ryan Broderick had found in his experiments in testing what now gains traction via tweet.
As summarized by Broderick:
“Twitter is using invisible subreddits via Topics to algorithmically organize tweets. Because the For You page isn’t chronological anymore, viral tweets can’t be as timely as they used to be. They have to be kind of evergreen. It helps if they’re commenting on something that’s already going viral. And it really helps if you post a thread, reply to yourself, or create some kind of discussion in the replies. There also seems to be a bigger emphasis on video now.”
Turns out, Ryan was correct – Twitter is now looking to promote more tweets in the ‘For You’ feed based on topical engagement, which Twitter defines at account level, by filtering certain accounts into topic categories, then using that as a guide to categorize the likely topic of each of their tweets.
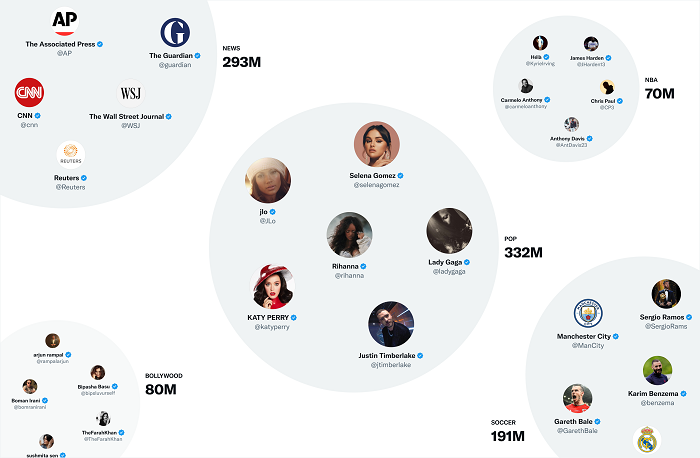
As per Twitter:
“One of Twitter’s most useful embedding spaces is SimClusters. SimClusters discover communities anchored by a cluster of influential users using a custom matrix factorization algorithm. There are 145k communities, which are updated every three weeks. Communities range in size from a few thousand users for individual friend groups, to hundreds of millions of users for news or pop culture. The more that users from a community like a Tweet, the more that Tweet will be associated with that community.”
The above image shows some of the largest Twitter ‘communities’, or topical collections based on Twitter’s algorithmic filtering.
Twitter says that this approach has become a key factor in deciding which of ‘out-of-network’ tweets to insert into your ‘For You’ feed, or which tweets to show you from accounts that you don’t follow. And with more and more of these recommendations being inserted into user feeds, it’s become a bigger driver of tweet exposure – though that’ll change again soon, when Twitter further restricts ‘For You’ recommendations to only tweets from paying subscriber accounts.
How that impacts the Twitter experience is anyone’s guess at this point, but it will fundamentally transform the ‘For You’ feed, at the least, by limiting the pool of source tweets that Twitter can pull from.
And if celebrities, in particular, don’t pay up, or stop tweeting as a result, that impact could be significant.
This is the most significant revelation of Twitter’s algorithmic overview, though there are several other interesting notes and points included in the documentation:
- For each user session, Twitter extracts around 1500 tweets that it believes will potentially be of interest to each person, before ranking them in the ‘For You’ feed
- The For You timeline currently consists of 50% In-Network Tweets (people you follow) and 50% Out-of-Network Tweets, on average
- Twitter also predicts the likelihood of engagement between two users. ‘The higher the Real Graph score between you and the author of the Tweet, the more of their tweets we’ll include’
- Another factor is the tweets that people you follow are engaging with – which is not a revelation, just a point of note
- Tweet ranking is conducted via a ‘~48M parameter neural network which is continuously trained on Tweet interactions to optimize for positive engagement (e.g. Likes, Retweets, and Replies)’. There’s no note, however, on how Twitter determines positive versus negative engagement in this context
That provides some interesting context as to how Twitter looks to rank tweets, and maximize exposure within the main ‘For You’ feed – though again, this will change on April 15th, when Twitter is going to switch to only showing tweets from paying users in its ‘For You’ recommendations.
Which, in some ways, makes a lot of this insight redundant – though I guess, if the working theory is that, eventually, most users will pay, then it could remain indicative for some time yet.
Except, they won’t.
Less than 1% of Twitter users are currently paying for Twitter Blue, and while the decision to remove ‘legacy’ blue ticks, and revert the ‘For You’ ranking process will drive some additional take-up, it seems unlikely to make Twitter Blue a significant consideration for the vast majority of Twitter users.
I guess, the other element to factor in, in this respect is that the vast majority of tweets come from very few users, with most Twitter profiles rarely tweeting themselves. Maybe, then, Twitter only needs a smaller collection of users to sign up for Blue in order to make it a more significant element in tweet ranking. But it still seems unlikely to produce better results in highlighting the most relevant content from across the app.
Regardless, it seems that Twitter is pushing ahead, and now, outside developers have more insight into how Twitter’s algorithm works, which will lead to a new flood of insights and pointers on how to game the system.
Twitter’s hope is that it also helps it improve its algorithms quickly. Maybe that happens as well. We’ll have to wait and see.

